 For the Jupyter Notebook that runs this project (HTML format) click this link:
For the Jupyter Notebook that runs this project (HTML format) click this link:
The Stroop Effect
Technologies utilized are Python, Pandas, Matplotlib, and SciPy (statistics).
To make our lives simple, our brains are wired to simply respond to stimuli. We have learned over the years that most stimuli are congruent. When the wind blows the trees move. As a result, it is not necessary to measure the velocity of the wind. You can simply look out the window of the house and if the trees are moving, it is windy.
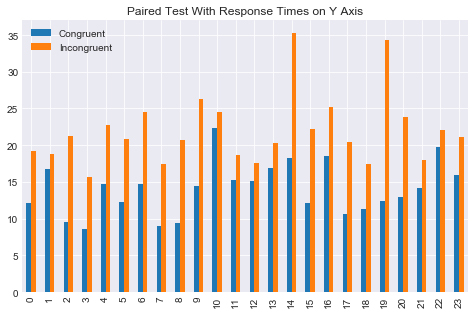 When we encounter stimuli that is incongruent, all this pre-set up wiring needs neutralizing for us to properly respond. It takes some time to process the stimuli and respond correctly since we need to fight thru all the pre-conditioning that we have developed over a life time. This difficulty is called the Stroop Effect.
When we encounter stimuli that is incongruent, all this pre-set up wiring needs neutralizing for us to properly respond. It takes some time to process the stimuli and respond correctly since we need to fight thru all the pre-conditioning that we have developed over a life time. This difficulty is called the Stroop Effect.
The Stroop Effect is all around us. An example would be a police lineup. Supposedly the perp is in the line up. It is congruent that the perp is there. So, the witness picks one of the people in the lineup. Yet, all that may be occurring is the Stroop Effect. While this may sound academic, for the person that just got picked out of the lineup for a major crime, it is far from academic.
The net is for a wide range of stimuli, there is built in congruency bias. This may be helpful for us to run our lives, but … when true thinking is required, it is a large hurdle for us to a) recognize that is what is occurring and b) continue with the process to think rationally instead of reflexively.
If this interests you please contact me. This project was done as part of my course work at Udacity (www.udacity.com) for the Data Analyst Nano Degree (DAND).


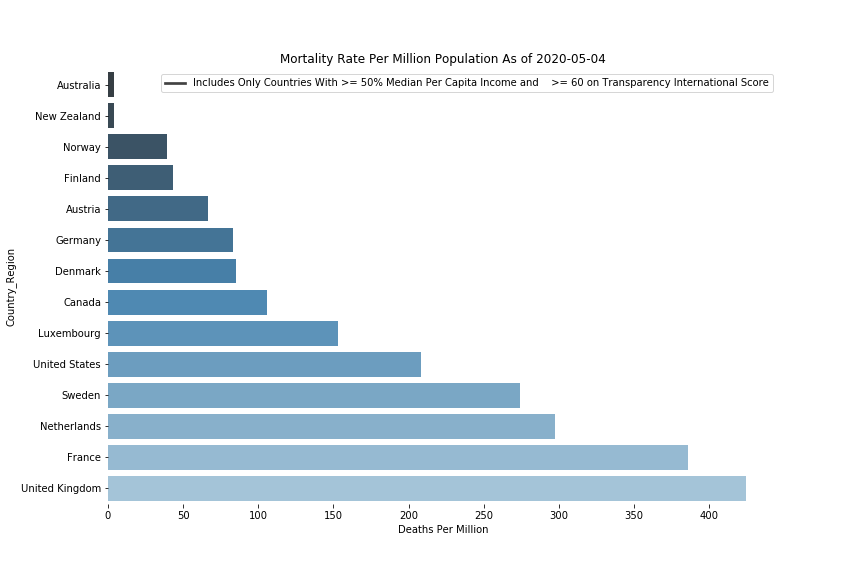
 I am currently working on a recommendation engine (Moon Shot Genius (MSG)) for buy/sell on lower priced stocks that are likely targets of insider training. The inputs are various social media feeds and stock market data.
I am currently working on a recommendation engine (Moon Shot Genius (MSG)) for buy/sell on lower priced stocks that are likely targets of insider training. The inputs are various social media feeds and stock market data.
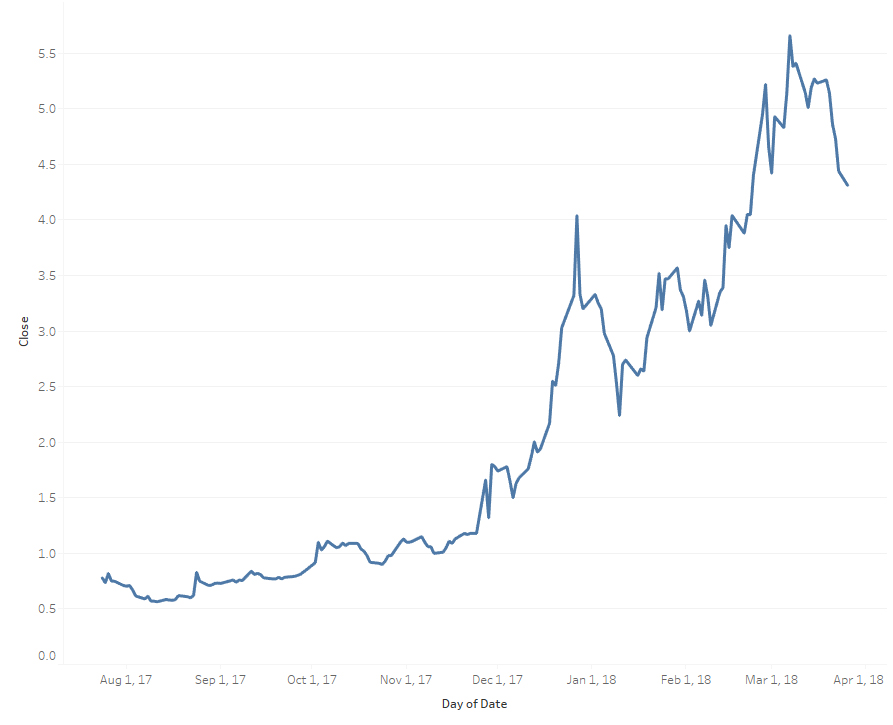
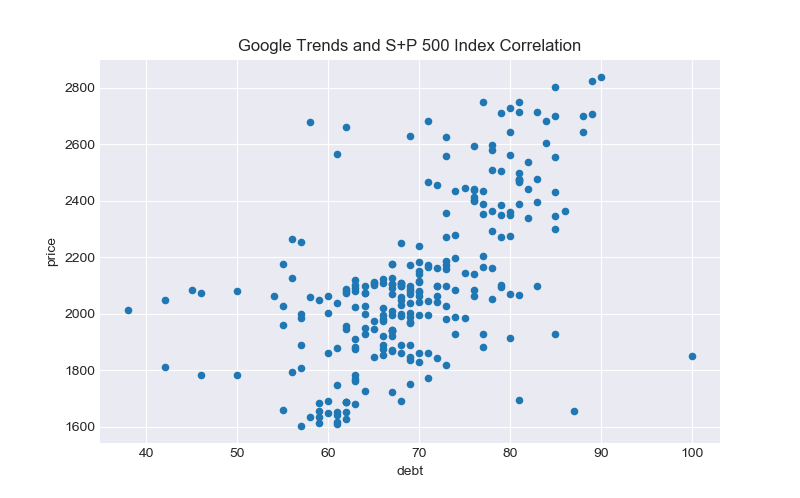 I am downloading data from Google Trends and merging it with historical S&P 500 index data looking for tradeable trends from April 2013 to April 2018. Correlation is promising (.58) and p-value was excellent at 4.5538 e-24 (VERY strong signal). I am working on creating a goal seeking algorithm that will yield specific signals to buy, sell or hold on a weekly basis (ergo sell on Friday, buy on Monday).
I am downloading data from Google Trends and merging it with historical S&P 500 index data looking for tradeable trends from April 2013 to April 2018. Correlation is promising (.58) and p-value was excellent at 4.5538 e-24 (VERY strong signal). I am working on creating a goal seeking algorithm that will yield specific signals to buy, sell or hold on a weekly basis (ergo sell on Friday, buy on Monday).

